Google Translate System Design
Introduction
Google Translate is a widely used language-translation service offered by Google. Powered by machine-learning (ML) models, it translates text between more than 130 languages and serves over a billion users as of 2024.
Clarifying Requirements
- Real-Time translation vs Batch Translation (Model Architecture)
- Text vs Audio vs Visual (Multi-modal)
- Cloud vs On-Device (Model size, Inference Optimization)
- Bilingual vs Multilingual
To simplify the problem, we will limit the scope to Batch, Multilingual, Text and Cloud translation system.
Frame the Problem as an ML Task
Specifying the System’s Input and Output
- Input: A sequence of words in the source language and the desired target language.
- Output: A sequence of words in the target language.
Choosing a Suitable ML Approach
Language translation is a classic sequence-to-sequence (seq2seq) task. Modern systems favor Transformer-based encoder-decoder models:
- Encoder – Converts the source sentence into contextual vectors.
- Decoder – Generates the target sentence token-by-token, attending to the encoder’s output.
Why Transformers?
- Handle long-range dependencies better than LSTMs/GRUs.
- The attention mechanism (originally proposed for translation [2]) lets the decoder focus on relevant source tokens.
- Encoder–decoder separation aligns naturally with translation.
Other models Choices
- Non-Autoregressive Transformers (NAT): Decodes all tokens in parallel → much faster, but typically lower quality. Often used for speed-sensitive applications Can be combined with knowledge distillation to improve performance.
- Prompt-based Translation using Decoder-only LLMs. Zero/few-shot with no retraining but Larger and slower than specialized MT models.
Data Preparation
Two data types feed the model:
- General data – Large-scale multilingual text from the internet.
- Translation data – ≈ 300 million sentence pairs (source + target).
Preparation focuses on translation data.
1. Primary Data: Parallel Corpora
This is the most crucial data, consisting of texts that are direct, sentence-by-sentence translations of each other. It forms the core training material for the model.
- Public Datasets: High-quality, formal corpora from official sources like the United Nations (UN) and the European Parliament (Europarl). These provide a strong, clean baseline.
- Web Crawling: Automatically crawling multilingual websites (like news sites or corporate pages) to find and extract translated pages. This provides a massive, diverse, but often “noisy” source of data that requires significant cleaning.
2. Data Expansion and Augmentation
Because high-quality parallel data is limited, several techniques are used to create more training examples:
- User Feedback: Leveraging the “Suggest an edit” feature and contributions from the Translate Community. This creates a continuous improvement loop by using real-world corrections to fix model weaknesses.
- Back-Translation: A powerful technique for low-resource languages. It involves taking monolingual text in the target language (e.g., German), using an existing model to translate it back to the source language (English), and then using this new synthetic {source, target} pair for training. This dramatically improves the translation’s fluency.
- Mining Comparable Corpora: This method is used when texts are about the same topic but are not direct translations (e.g., English and German news articles about the same event).
1 · Text Pre-processing
- Remove missing or noisy pairs (HTML, wrong language).
- Deduplicate sentence pairs.
- Handle named entities with placeholders (e.g.,
ENTITY_1). - Skip older steps (lower-casing, stop-word removal, stemming, punctuation stripping) because modern Transformers learn these patterns directly.
Preprocessing Steps — Modern Translation Pretraining
🔎 1️⃣ Data Cleaning & Deduplication
| Task | Purpose |
|---|---|
| Remove noisy sentences | Drop sentence pairs with very long or very short sequences, or mismatched alignments. |
| Filter profanity / sensitive content | Ensure safe outputs. |
| Deduplicate | Remove duplicate sentence pairs and repeated monolingual data (web crawl has lots of duplication). |
| Script normalization | Normalize Unicode (NFC/NFD), convert different scripts consistently (e.g., Simplified ↔ Traditional Chinese). |
✅ Why: Reduces noise → improves model generalization.
🔎 2️⃣ Language Identification & Tagging
| Task | Purpose |
|---|---|
| Language detection | Auto-identify language of monolingual data (and confirm for parallel pairs). |
| Assign language tags | E.g., add >>fr<< or >>zh<< to source text so the model knows which language to translate into. |
✅ Why: Enables multilingual pretraining and zero-shot/few-shot transfer.
🔎 3️⃣ Tokenization
| Task | Purpose |
|---|---|
| Subword tokenization (SentencePiece, BPE, WordPiece) | Split words into common subword units to handle rare/unseen words. |
| Multilingual vocabulary | Train a shared tokenizer across all languages. |
✅ Why: Handles vocabulary for hundreds of languages in a scalable way.
🔎 4️⃣ Alignment Verification (Parallel Data)
| Task | Purpose |
|---|---|
| Length ratio checks | Filter out sentence pairs with extreme length mismatches. |
| Translation quality scoring (optional) | Use tools like LASER or BLEU filtering to keep only high-quality sentence pairs. |
✅ Why: Ensures that paired data teaches the model correct alignments.
🔎 5️⃣ Corruption / Masking (for Monolingual)
| Task | Purpose |
|---|---|
| Noise injection (shuffling, masking, deletion) | Prepare monolingual data for Denoising Auto-Encoding (DAE) or MLM tasks. |
✅ Why: Teaches encoder-decoder models to recover from corrupted inputs → boosts robustness and learning.
🔎 6️⃣ Sampling & Balancing
| Task | Purpose |
|---|---|
| Upsampling low-resource languages | Increase frequency of rare languages in the training stream. |
| Downsampling high-resource languages | Prevent overfitting to dominant languages like English or Spanish. |
✅ Why: Balances the multilingual training data.
🔎 7️⃣ Back-Translation (for Monolingual → Synthetic Parallel)
| Task | Purpose |
|---|---|
| Translate monolingual target sentences back into source languages | Create synthetic parallel data when human-translated data is missing. |
✅ Why: Expands training data for low-resource pairs.
2 · Text Tokenization
Word-level vocabularies explode in size across 130+ languages, so we use sub-word tokenization—specifically Byte-Pair Encoding (BPE) .
Example token-to-ID mapping:
| Token | ID |
|---|---|
<BOS> |
0 |
<EOS> |
1 |
| walking | 2 |
| bonjour | 3 |
| hello | 4 |
| fantastique | 5 |
| … | … |
1. Byte-Pair Encoding (BPE)
Used in: GPT-2, RoBERTa
- Idea: Start from characters, iteratively merge the most frequent pairs of tokens.
- Goal: Build a vocabulary of subwords to reduce OOV (out-of-vocabulary) issues.
- Deterministic: Given a trained vocabulary, tokenization is consistent.
Example:
Training corpus: "low lower newest widest"
- Start with chars:
l o w,l o w e r, etc. - Find most common pair (e.g.,
'e'+'r'→'er'), merge into'er' - Repeat until vocab size is met.
Tokenize "lower" → ['low', 'er'] if 'low' and 'er' exist in vocab.
2. Byte-Level BPE (BBPE)
Used in: GPT-3, GPT-4
- Extension of BPE, but operates on bytes, not Unicode characters.
- Handles all inputs (e.g., emojis, unseen scripts) without needing pre-normalization.
- More robust to misspellings and multilingual input.
- deals with unseen or non-standard characters best, since all text (even unknown Unicode symbols) can be represented as bytes
Example:
Input: "apple 🍎"
- Break into raw bytes:
['a', 'p', 'p', 'l', 'e', ' ', '🍎'] - Apply merges on bytes to form subwords:
['app', 'le', ' ', '🍎'](assuming'app'and'le'exist)
3. Unigram Language Model
Used in: SentencePiece (T5, ALBERT)
- Trains a probabilistic model of subword units.
- Starts with many subwords, gradually removes the least likely ones.
- At inference, selects the most likely token sequence via Viterbi.
Example: "international"
May be tokenized as ['inter', 'national'] or ['intern', 'ation', 'al'] depending on highest probability.
4. WordPiece
Used in: BERT
- Similar to BPE, but selects merges to maximize likelihood of training data under a language model.
- Always starts with a whole word, splits into subwords with
##prefix for non-initial parts.
Example: "unhappiness"
→ ['un', '##happiness'] or ['un', '##hap', '##pi', '##ness'] depending on vocab.
Summary Table:
| Algorithm | Used In | Key Feature | Handles OOV? | Probabilistic? |
|---|---|---|---|---|
| BPE | GPT-2, RoBERTa | Merges frequent char pairs | Yes | No |
| Byte-level BPE | GPT-3, GPT-4 | Merges on byte sequences | Yes | No |
| WordPiece | BERT | Greedy merging with LM scoring | Yes | No |
| Unigram LM | T5, ALBERT | Picks best subwords probabilistically | Yes | Yes |
Let me know if you’d like to visualize token merges step by step.
Model Development
Architecture Overview
Encoder-decoder Transformer components:
| Component | Encoder | Decoder |
|---|---|---|
| Token Embedding | ✅ | ✅ |
| Positional Encoding | ✅ | ✅ |
| Self-Attention | Full (bi-directional) | Masked (causal) |
| Cross-Attention | — | ✅ |
| Prediction Head | — | ✅ |
Key differences:
- Cross-Attention Layer – Decoder attends to encoder outputs.
- Masked Self-Attention – Decoder can’t see future tokens.
- Prediction Head – Linear + soft-max layer produces token probabilities.
Other key information:
- Positional Embeddings: Rope, Sinusoidal
- Residual Connection
- MOE architecture
- Self-Attention, Cross-Attention
Training Strategy by Alex
| Stage | Data | Objective | Loss |
|---|---|---|---|
| Unsupervised Pre-training | Multilingual general text | Masked Language Modeling (MLM) | Cross-entropy |
| Supervised Finetuning | Parallel sentence pairs (bilingual) | Next-token prediction | Cross-entropy |
- Bilingual vs. Multilingual:* This design opts for bilingual models (higher accuracy per pair, at higher ops cost).
ML Objective & Loss Function — Revised ✍️
Below is a tighter, more technically precise version of the “ML objective and loss function” section, organised to show why each design choice matters when training a Neural Machine Translation (NMT) system.
1 | Pre-training: Learning Multilingual Representations
Data
We keep the multilingual portions of large-scale corpora (C4, Wikipedia, Stack Exchange, Common-Crawl, etc.) and drop only the languages we never intend to translate. This maximises coverage while avoiding label noise from irrelevant scripts.
Objective — Masked Language Modeling (MLM) with span corruption
1 | Input : The quick brown <mask> jumps over the <mask> dog . |
- Why not next-token prediction? In unsupervised pre-training the decoder could simply echo the current token, so the encoder would learn little. MLM forces the encoder to build a genuine contextual representation that the decoder must rely on.
- Span masking (T5-style) hides contiguous chunks, encouraging longer-range reasoning and reducing the number of prediction steps.
- 15 % of tokens are selected; 80 % are replaced by
<mask>, 10 % by random tokens, 10 % left unchanged to give the model noise robustness.
Loss — Cross-entropy over only the masked positions
with optional label smoothing (ε ≈ 0.1) for better generalisation.
2 | Supervised Fine-tuning: Turning a General LM into a Translator
With sentence-aligned pairs
- Encoder ingests the full source sentence
. - Decoder is trained with teacher forcing: it receives the gold target prefix
and predicts the next token . - Loss — Token-level cross-entropy on all target positions
plus the same label-smoothing trick.
Training Strategy for Modern Multilingual NMT Systems
Modern multilingual Neural Machine Translation (NMT) models, such as those used in services like Google Translate, follow a multi-stage training process to achieve high performance across many language pairs. The pipeline typically includes the following stages:
1. Pretraining (Cross-Lingual Language Modeling)
Purpose:
Learn universal language patterns and cross-lingual representations before any translation-specific training.
Data Used:
Large-scale monolingual corpora from many languages, often mined from web sources.
Training Objectives:
- Masked Language Modeling (MLM): Predict masked tokens in a sentence.
- Denoising Auto-Encoding: Reconstruct corrupted text sequences.
- Translation Language Modeling (less common): Learn cross-lingual alignment using bilingual input.
Model Behavior:
The model learns general linguistic features across languages, which helps especially in low-resource scenarios.
2. Supervised Fine-Tuning (Translation Modeling)
Purpose:
Teach the model how to translate between languages using sentence-aligned parallel corpora.
Data Used:
Large-scale parallel corpora, mostly English-centric but also covering non-English pairs. Synthetic data (e.g., back-translated text) is also used to supplement low-resource languages.
Training Strategy:
- All language pairs are trained together in a single model (many-to-many).
- Special tokens are added to indicate target language.
- Shared subword vocabulary (e.g., BPE or SentencePiece) is used.
- Sampling strategies are applied to balance low-resource and high-resource languages.
Augmentation Techniques:
- Back-Translation: Use a trained model to generate synthetic source sentences from target-language monolingual text.
- Knowledge Distillation: Train on simplified outputs from a teacher model.
- Forward-Translation: Less common, used if target-language monolingual data is limited.
Zero-shot Capability:
A well-trained multilingual model can often translate between unseen language pairs by transferring knowledge from related pairs.
3. Domain Adaptation (Specialized Fine-Tuning)
Purpose:
Improve translation quality in specific domains like healthcare, law, or conversational text.
Data Used:
Smaller, domain-specific parallel corpora, sometimes supplemented by synthetic domain data via back-translation.
Training Strategy:
- Fine-tune the general multilingual model on in-domain data.
- Use techniques like early stopping, data mixing, or regularization to avoid overfitting.
- Multi-stage adaptation (e.g., from multilingual → language pair → domain) often performs best.
- Lightweight adapter modules can be added to specialize models per domain without altering the base model.
Recent Trends and Innovations
- Scaling Up: Large sparse models (e.g., Mixture-of-Experts) enable translation across hundreds of languages efficiently.
- Data Mining: Automated mining of high-quality sentence pairs from web data improves coverage, especially for low-resource languages.
- Balancing Techniques: Sampling strategies and vocabulary sharing improve performance across imbalanced datasets.
- LLMs for Translation: Large language models trained on multilingual data (e.g., GPT-4, PaLM) show strong translation abilities even without dedicated parallel data. They’re now being adapted for NMT use or employed to generate synthetic training data.
- Multitask and Modular Architectures: Supporting multiple tasks or inserting domain-specific adapters increases flexibility and robustness.
End-to-End Summary
Multilingual NMT systems are trained in stages—starting with monolingual self-supervised learning, followed by supervised translation training using real and synthetic parallel data, and optionally domain-specific fine-tuning. The training pipeline is carefully designed to handle large-scale, multilingual data while balancing quality across languages and domains. Ongoing advances in architecture, data quality, and LLM integration continue to push translation quality and coverage.
2. Training Data Collection
A. Parallel Corpora (Supervised)
Sources:
- Public Datasets: WMT, OPUS, Europarl, UN Corpus.
- Web Crawls: Filtered bilingual websites (e.g., Common Crawl, ParaCrawl).
- Official Documents: Government/legal text in multiple languages.
B. Monolingual Corpora (Unsupervised/Pretraining)
Sources:
- C4, Wikipedia, CCNet, OSCAR, Gigaword, BookCorpus.
- Cleaned and language-labeled for the relevant set of translation languages.
C. Quality Filtering Techniques
- Length Ratio Filtering: Removes sentence pairs with large length mismatch.
- Language Identification: Ensures text is in the expected language.
- Dual-Model Agreement / BLEU Filtering: Keep only pairs with agreement between two translation models or high BLEU.
- Noise Detection: Drop automatically translated or low-confidence samples.
D. Data Balancing
Address low-resource language imbalance by:
- Oversampling rare languages.
- Sampling temperature strategies (e.g., square-root or inverse frequency).
- Synthetic data augmentation via back-translation or pivoting.
Sampling Strategies in Generative Models
- Deterministic methods (e.g., greedy search, beam search)
- Stochastic methods (e.g., multinomial sampling, top-k, top-p)
In this chapter, we choose beam search for two key reasons:
Why Beam Search?
Translation Accuracy:
Beam search evaluates multiple candidate sequences and selects the most probable one, often resulting in more accurate and fluent translations.Consistency:
As a deterministic method, beam search always produces the same output given the same input. This is crucial for translation systems, where consistency and reliability outweigh diversity. Unlike creative applications, translation rarely benefits from random or surprising outputs.
In contrast, stochastic sampling methods are better suited for tasks where diversity and creativity are desired, such as storytelling or dialogue generation.
Comparison: Deterministic vs. Stochastic Sampling
| Characteristic | Deterministic Methods | Stochastic Methods |
|---|---|---|
| Approach | Follows a predictable decision process | Samples from a probability distribution |
| Efficiency | Less efficient (tracks multiple paths) | More efficient due to randomness |
| Output Quality | Coherent and predictable | Diverse and imaginative |
| Risk | May produce repetitive sequences | May generate inappropriate or off-topic text |
| Best For | Tasks requiring consistency (e.g. translation) | Tasks requiring creativity (e.g. story generation) |
| Common Methods | Greedy search, beam search | Multinomial sampling, top-k, top-p sampling |
Evaluation
Offline Metrics
Key Metrics:
- BLEU (Bilingual Evaluation Understudy): One of the oldest and most widely used metrics, BLEU measures the n-gram precision between the machine-translated text and the reference translations. It focuses on the similarity of the output to high-quality human translations. While fast and easy to calculate, it can sometimes penalize translations that are semantically correct but lexically different from the references.
- METEOR (Metric for Evaluation of Translation with Explicit ORdering): METEOR is an improvement upon BLEU that considers synonymy and stemming, leading to a better correlation with human judgment. It aligns words between the machine and reference translations and calculates a score based on precision, recall, and a fragmentation penalty.
- COMET (Cross-lingual Optimized Metric for Evaluation of Translation): A more recent and powerful metric, COMET leverages large-scale pre-trained language models to assess the semantic similarity between the source text, the machine translation, and the reference translation. It has shown a very high correlation with human ratings.
- BERTScore: This metric utilizes contextual embeddings from BERT to compare the similarity of tokens in the candidate and reference translations. This allows it to capture semantic nuances that n-gram-based metrics might miss.
Human Evaluation
- Adequacy and Fluency: This is a classic approach where human judges rate translations on two scales:
- Adequacy: How well the meaning of the source text is preserved in the translation.
- Fluency: How natural and grammatically correct the translated text sounds in the target language.
- Direct Assessment (DA): In this method, human annotators assign a single, continuous score to a translation, often on a scale of 0 to 100, reflecting its overall quality. This approach has become increasingly popular in major translation conferences like WMT (Workshop on Machine Translation).
- Ranking: Evaluators are presented with translations from multiple NMT systems for the same source sentence and are asked to rank them from best to worst. This is a relative measure that is useful for comparing the performance of different models.
LLM as a Judge
The typical setup involves prompting an LLM with the source sentence, the candidate translation(s), and optionally a reference translation. The LLM is then instructed (via a carefully designed prompt) to perform tasks such as:
- Scoring translations on dimensions like adequacy, fluency, and faithfulness.
- Choosing the better translation between multiple candidates (preference ranking).
- Providing natural language feedback on errors or strengths in the output.
LLMs can handle multilingual input and adapt to complex linguistic nuances, making them especially valuable for evaluating low-resource or morphologically rich languages where human evaluation is expensive or infeasible.
Companies often use few-shot or zero-shot prompting, and sometimes fine-tune LLMs with supervised data (e.g., human-labeled translation comparisons) to improve consistency and alignment with human judgments. These LLM-based evaluations correlate more closely with human ratings than BLEU scores and offer significant efficiency and scalability benefits.
For example:
- Google uses LLMs internally to benchmark translation quality across hundreds of languages.
- OpenAI and others use LLMs to evaluate summarization, QA, and translation outputs in human preference studies.
- Meta’s SEED framework and Anthropic’s Constitutional AI both involve LLM-based feedback loops to refine and assess generation quality.
Online Metrics
- User feedback – Rating prompt after translation (Figure 3.25).
- User engagement – Usage frequency, session length, retention.
Overall ML System Design
1 · Language Detector
An encoder-only Transformer classifies the input language via:
- Average pooling → prediction head, or
- Last-token representation → prediction head.
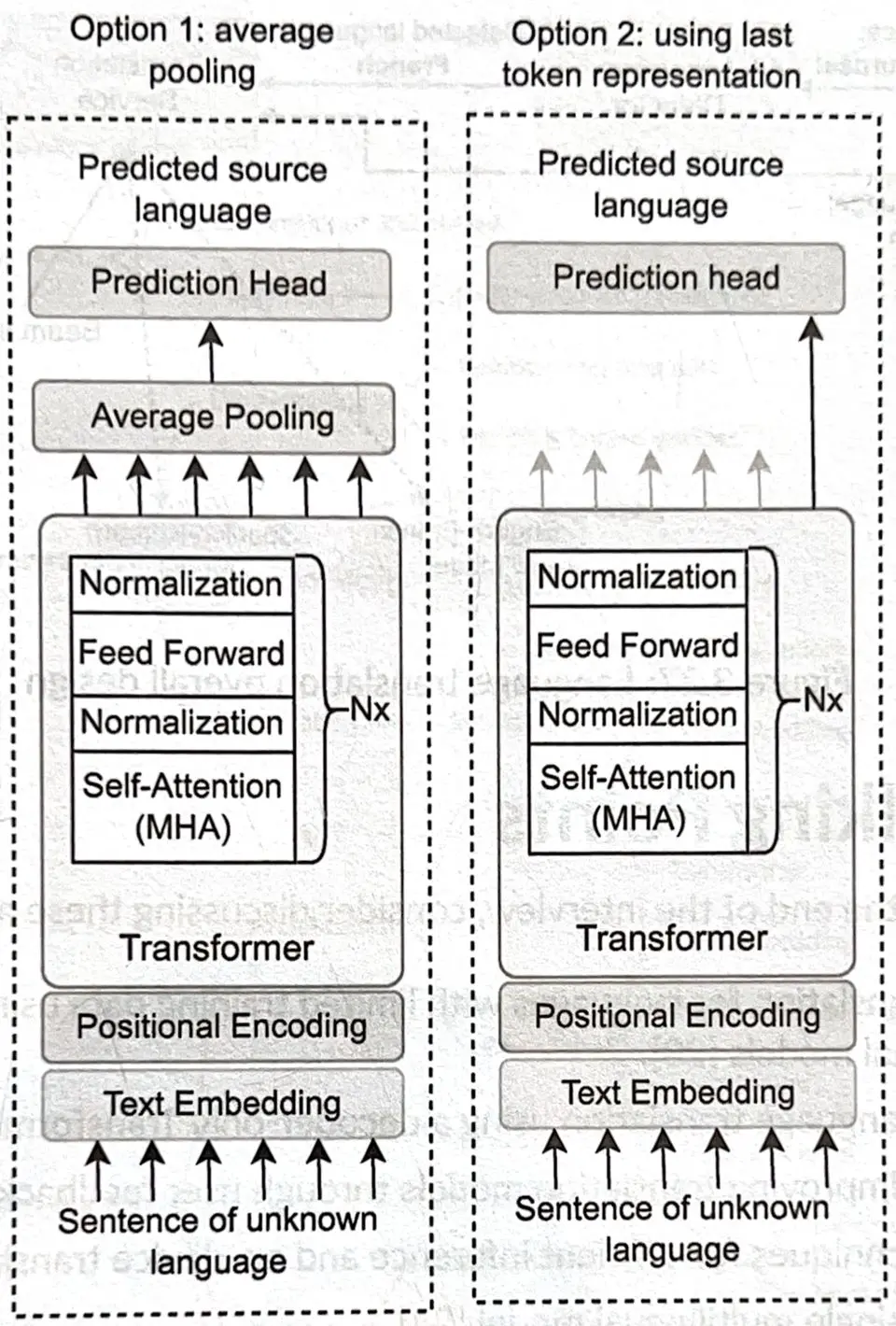
2 · Translation Service
- Detect language.
- Route to correct bilingual model.
- Perform beam search decoding.
- Detokenize and return text.
Other Talking Points
If time remains, discuss:
- Model compression (quantization, distillation).
- On-device translation (Apple, offline mode).
- Handling new languages with limited corpora (few-shot, adapter layers).
- Real-time constraints for mobile typing suggestions.
Real-Time Translation:
Replace Full-Sequence Encoder-Decoder with Streaming Models:
- Traditional Transformer waits for the entire source sentence before producing output → too slow for real-time.
- Use a streaming architecture to process input incrementally:
Architectural Options:
| Strategy | Description | Example |
|---|---|---|
| Chunk-based Transformer | Break input into fixed-size overlapping windows | SimulTrans, STACL |
| Monotonic Attention | Enforces left-to-right or wait-k policy | MoChA, Wait-k Transformer |
| Transducer models | Encoder-decoder-decoder (non-attention based) | RNN-T, Recurrent Neural Aligner |
| Streaming Conformer (for speech) | Use causal attention and limited context for audio | Google’s real-time ST model |
🛠 Techniques to Apply:
- Use causal self-attention (no future tokens).
- Use incremental decoding (no full-sequence softmax).
- Add latency-controlled decoding policies (e.g., wait-k beam search).
On-Device Translation:
Replace Heavy Transformer with Lightweight, Quantized, and Distilled Models:
Architectural Options:
| Model | Type | Notes |
|---|---|---|
| MobileBERT, TinyBERT | Lightweight Transformers | Good encoder for on-device NMT |
| DistilBART, DistilmBART | Distilled encoder-decoder | Smaller decoder with similar quality |
| mBART + pruning/quantization | Multilingual | Use only specific heads/layers |
| FNet | Replaces self-attn with Fourier Transform | Super fast & small |
| Linear Attention Models (Performer, Linformer) | Approximate attention for low-memory devices | Good for constrained decoding |
🛠 Key Optimization Techniques:
- INT8/INT4 quantization (QAT or PTQ)
- Weight pruning + layer dropout
- LoRA/Adapters to allow per-language tuning without retraining the full model
- Deploy with ONNX, TensorRT, TensorFlow Lite, or CoreML