原文链接 https://arxiv.org/pdf/2503.07703
导言
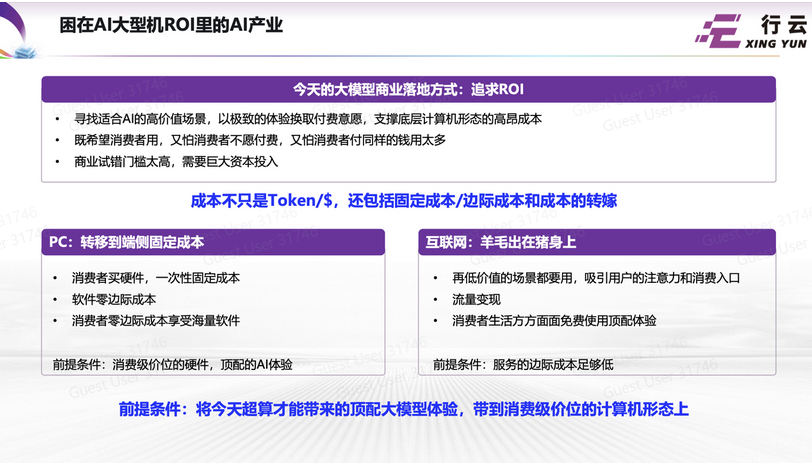
豆包团队针对现有flux、Midjourney、SD3.5等模型对于1.模型长文本和多语言(中文)能力不足;2.不能理解中国文化 的问题,提出了seedream 2.0中英双语大模型。模型的创新性在于数据处理平台,双语言编码器以及后训练。这是一份33页的技术报告,写的非常详细。数据环节的解释非常清晰,编码器的结构和后训练环节的创新也很有亮点。尤其是后训练部分,细节多到令人感动。这篇文章让我感受到字节/豆包的底蕴,不愧是不惜血本挖人的宇宙厂,科研能力和产品能力都没得说。
数据
数据的组成包括高质量数据,分布保持数据,知识注入,以及一些针对性补充数据。高质量数据和其他模型的数据集差不多(clarity,aesthetic),分布保持是做down sampling,在保持原始数据分布情况下减少低质量数据。知识注入包括了很多高质量的中文图文数据,并且其中一部分是只有中国文化有的数据。
数据清理分三步的漏斗系统。第一步,计算quality score, structure score(水印,logo),然后用ocr去identify text。不符合的数据会被剔除;第二步,分层的进一步筛选。第三步,captioning 和 re-captioning。captioning的部分,豆包会对每一张图做 generic (长句子,短句子) 和 specialized (图片中的文字,美学,想象力)标注。
豆包还设计了一个active learning engine,先标注少量数据训练分类器,再利用分类器从无标注图像中挑选有价值的样本继续标注,形成 “标注 — 训练 — 再筛选” 的循环,逐步完善数据集。
双语言编码器
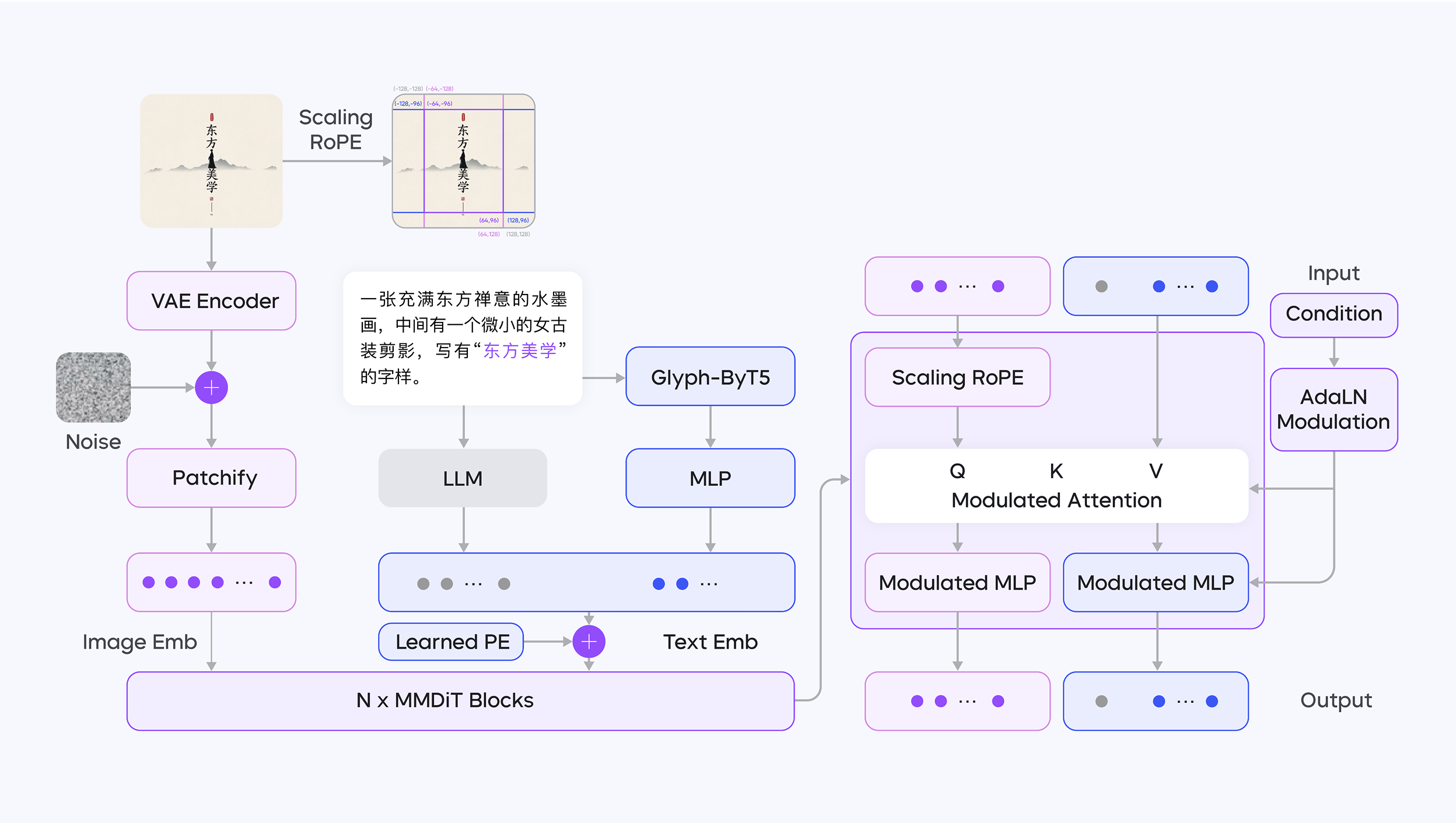
现有扩散模型一般用clip或者t5当作text encoder,因为他们的embeddings 分布比较符合扩散模型。LLM虽然能力很强,但是它的数据分布不对。为了解决这个情况,豆包收集了高质量中文数据微调了decoder only 大模型,并针对渲染文本的字形特征,同时使用 LLM(大语言模型,作为文本编码器)和 ByT5 模型进行编码。