Original link: https://arxiv.org/pdf/2503.07703
Introduction
The Doubao team proposed Seedream 2.0, a Chinese-English bilingual large image generation model, to address existing problems in models such as Flux, Midjourney, and SD3.5: 1. insufficient long-text and multilingual, especially Chinese, ability; 2. inability to understand Chinese culture. The model’s innovations are in the data processing platform, bilingual encoders, and post-training. This is a 33-page technical report, and it is written in great detail. The explanation of the data part is very clear, and the innovations in encoder structure and post-training are also quite impressive. The post-training section in particular has so many details that it is moving. This paper made me feel ByteDance/Doubao’s depth. It really deserves to be the universe company that spends without blinking to recruit people. Its research ability and product ability are both very strong.
Data
The data consists of high-quality data, distribution-preserving data, knowledge injection, and some targeted supplementary data. High-quality data is similar to other models’ datasets, such as clarity and aesthetic quality. Distribution preservation uses downsampling to reduce low-quality data while preserving the original data distribution. Knowledge injection includes a lot of high-quality Chinese image-text data, and part of it is data that only exists in Chinese culture.
Data cleaning uses a three-step funnel system. First, it computes a quality score and structure score, such as watermark and logo, and then uses OCR to identify text. Data that does not meet the requirements is removed. Second, it applies further hierarchical filtering. Third, it performs captioning and re-captioning. For captioning, Doubao creates both generic annotations, long sentences and short sentences, and specialized annotations, such as text in the image, aesthetics, and imagination, for every image.
Doubao also designed an active learning engine. It first annotates a small amount of data to train a classifier, then uses the classifier to select valuable samples from unlabeled images for further annotation, forming a loop of “annotation - training - selection again” and gradually improving the dataset.
Bilingual encoders
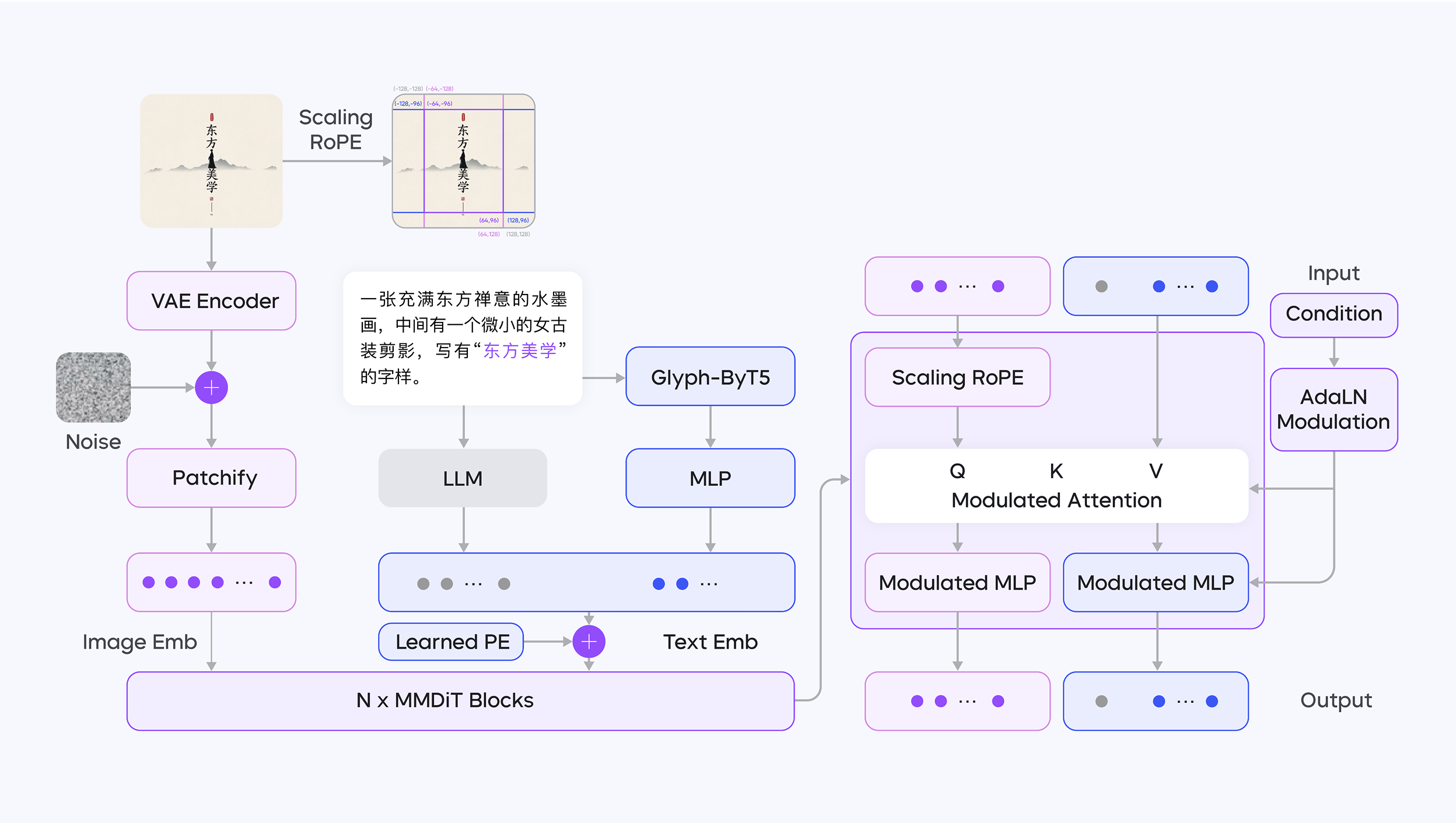
Existing diffusion models usually use CLIP or T5 as the text encoder because their embedding distributions fit diffusion models relatively well. Although LLMs are very capable, their data distribution is not right. To solve this, Doubao collected high-quality Chinese data to fine-tune a decoder-only large model. For glyph features in rendered text, it uses both an LLM, as the text encoder, and ByT5 for encoding.
The LLM is good at capturing the overall semantics of text, especially complex Chinese contexts such as poetry and traditional folk descriptions, and it has a deep understanding of cultural meaning. It can learn Chinese cultural features from massive data and ensure that generated images accurately express text semantics. For example, when generating images that include traditional Chinese elements, it can accurately convey cultural details. As a bilingual encoder, the LLM supports Chinese-English semantic alignment, allowing the model to maintain cross-language consistency when processing bilingual prompts.
Glyph-Aligned ByT5 focuses on character-level feature processing and solves issues such as messy layout and repeated characters in text rendering. For example, in long text or complex typography such as vertical Chinese text and calligraphy fonts, it uses character-level embedding alignment to achieve high-precision text layout generation, ensuring that text arrangement follows visual logic. It handles details of multilingual characters more finely, improving the model’s generality across different language text rendering tasks, especially for non-English text such as Chinese and Japanese.
The diffusion architecture is DiT. It uses resolution-aware Scaling ROPE, so the same image can have similar positional encoding across different sizes.
Post-training
Post-training is divided into four stages:
- Continue Training (CT) and Supervised fine-tuning (SFT) stages remarkably enhance the aesthetic appeal of the model;
- Human Feedback Alignment (RLHF) stage significantly improves the model’s overall performance across all aspects via self-developed reward models and feedback learning algorithms;
- Prompt Engineering (PE) further improves the performance on aesthetics and diversity by leveraging a fine-tuned LLM;
- Finally, a refiner model is developed to scale up the resolution of an output image generated from our base model, and at the same time fix some minor structural errors.
CT uses two kinds of data: high-quality data selected by machines from the training data, and art/photography/design works selected by humans, mixed in a certain ratio. During training, it uses a Value Mixing Control (VMix) Adapter, which can better distinguish content and aesthetic prompting and make the overall model generate better-looking images. SFT integrates some labeled positive samples and some model-generated negative samples for further training.
RLHF uses a bilingual CLIP as the reward model, and also uses an image-text alignment RM, an aesthetic RM, and a text-rendering RM.
PE is also divided into two stages. The first stage is supervised LLM fine-tuning, building a PE model u -> r, where u is the original prompt and r is the model-improved prompt. The first training method is to continuously improve r so that u can generate a good image through r. The second is to find high-quality text pairs and continuously reduce the description in r to recover u. The second stage is RLHF: it generates many prompts through the first-stage PE, then manually selects positive and negative pairs for RL.
The refiner also has two stages. The first stage is 1024-resolution scaling. The second stage finds some high-quality texture data, downgrades it, and then uses this data to train a texture model to guide the refiner model.
Instruction-Based Editing
It uses the self-developed SeedEdit. Different from other solutions, SeedEdit uses diffusion as the encoder. To improve face consistency, it uses internal ID/IP models and collects many ID/IP images under different conditions. At the same time, the model structure introduces perception loss, or face loss, to maintain face consistency.
Model acceleration
Trajectory Segmented Consistency Distillation (TSCD) divides the time interval [0,T] into k segments, and gradually reduces them during training. It also fine-tunes quantization, supporting quantization for different parts of the model.